 合作
合作
 咨询
咨询 帮助
帮助
 数据标注咨询
数据标注咨询 
- 作者:dianwo
- 发表时间:2019-09-16 09:55
- 来源:未知
本文来自微信公众号“大数据文摘”(ID:BigDataDigest),作者刘俊寰

想到可以利用AI进行诈骗的可不止一些初创公司,当下AI技术如此发达,换脸都能轻松实现,那声音呢?
提到这种变声技术,可能最先想到的是《名侦探柯南》中柯南使用的蝴蝶结变声器,柯南正是利用阿笠博士的这个发明把“沉睡的毛利小五郎”捧上了侦探界的神坛。
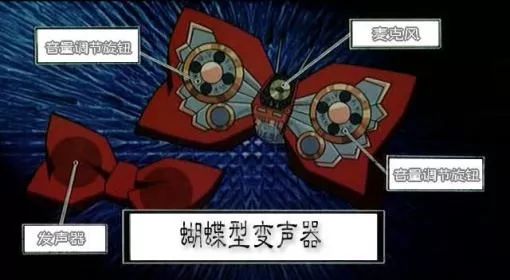
但是试想,如果有人把这项技术用于诈骗,是不是顿时后背发凉?
据《华尔街日报》报道,今年3月份,有犯罪分子就使用了类似的AI技术,他们成功模仿了英国某能源公司在德国 母公司CEO的声音,诈骗了220,000欧元(约1,730,806人民币)。
网络犯罪专家称,这是黑客攻击中利用AI技术的一次不寻常案例。
三次电话,损失22万欧元
案发时,该公司的CEO误以为他正在与他的老板,也就是德国 母公司的CEO通电话,老板要求他将资金汇给匈牙利供应商。据该公司的保险公司Euler Hermes Group SA称,来电者表示该请求非常紧急,要求行政人员在一小时内付款。
慕尼黑的金融服务公司Allianz SE旗下子公司Euler Hermes的欺诈专家Rüdiger Kirsch说,犯罪分子总共打了三次电话。220,000欧元转移后,他们打电话说母公司已经转移资金偿还英国公司,然后他们在当天晚些时候进行了第三次电话会议,再次冒充首席执行官,要求第二次付款。由于转账偿还资金还没有到来,而第三次电话是来自奥地利的电话号码,行政部门开始怀疑,没有支付第二笔款项。
根据Kirsch先生的说法,转入匈牙利银行账户的资金随后转移到墨西哥并分发到其他地方,调查人员没有发现任何嫌犯,而且,Euler Hermes承担了受害公司索赔的全部金额,但没有处理要求追回涉及AI犯罪损失的索赔。
Kirsch先生认为,使用AI诈骗对公司来说是新的挑战,传统网络安全工具无法发现欺骗性的声音,而黑客往往就是使用商业语音生成软件进行攻击。Kirsch先生用这种产品录制了自己的声音,并说复制版本听起来很真实。
目前还不清楚攻击者是否使用机器人对受害者的问题作出反应。欧洲刑警组织欧洲网络犯罪中心战略负责人菲利普·阿曼说,如果他们这样做,执法当局调查可能会更加困难。Kirsch先生说,警方对此案的调查已经结束,欧洲刑警组织没有参与。
从语音转发到语音复制,声音还有多少可信度?
其实,执法当局和AI专家早有预言,犯罪分子将使用AI进行自动化网络攻击。无论是谁策划了这一事件,他们都已经使用AI软件成功地通过电话模仿了德国高管的声音。
虽然有欧洲官员表示,这是他们第一次听说在欧洲发生AI变声语音诈骗,而且犯罪分子明显依赖于AI变声技术,但这远非第一起利用语音进行诈骗的案件,在国内,变声技术早已被用于网络诈骗中,人民网微博最早在去年八月就发布了利用微信语音诈骗的案件消息。
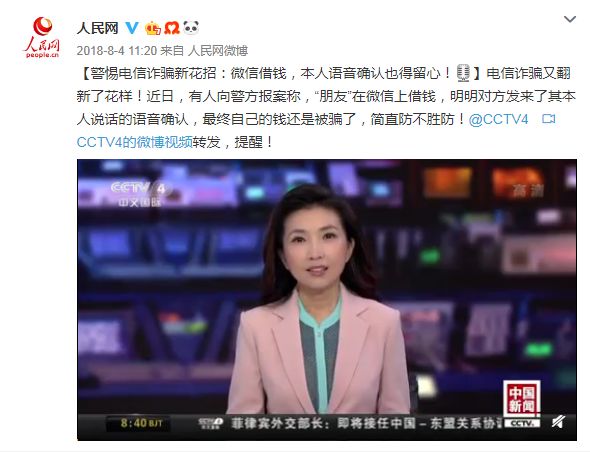
犯罪分子利用的是一种名叫“增强版微信”的软件,这种“增强版微信”具有能够转发语音消息、克隆好友朋友圈、看到对方撤回的消息等功能。
据称,这些功能都是服务于一些“特殊用户”的,比如自定义位置,就能让客户在国内实现海外“云度假”,或者让一些商家假装自己是“海外代购”等。
脱离微信而言,利用声音合成技术也已经实现了语音复制。语音数据分析
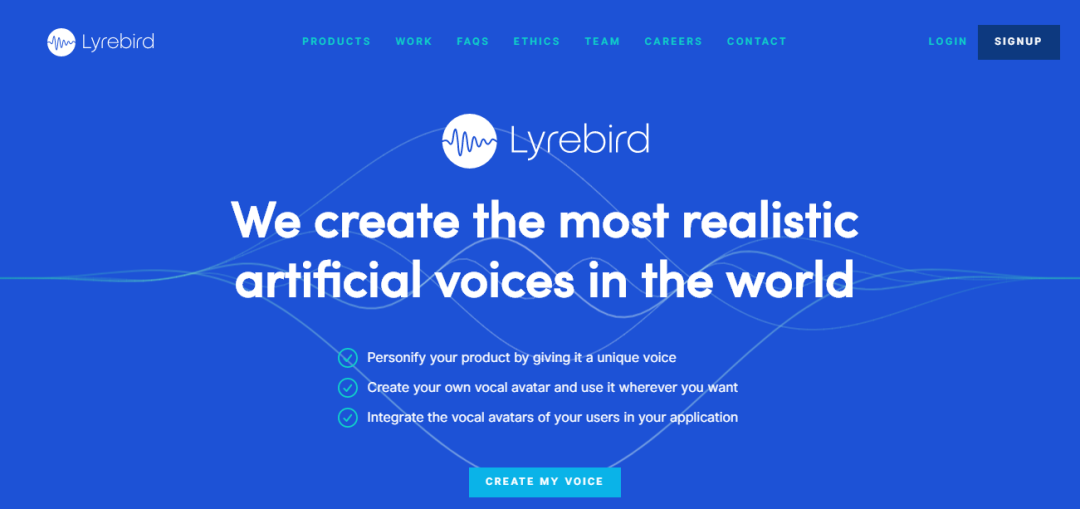
去年,三名蒙特利尔大学博士联合创办的名为“琴鸟”(Lyrebird)的公司开发出了一种“语音合成”技术,只要对目标人物的声音进行1分钟的录音,丢给“Lyrebird”处理,就能得到一个特别的密钥,利用这个密钥可以生成目标人物任何想说的话。
“琴鸟”(Lyrebird)不仅能利用语音模仿演算模仿出任何人的声音,还能在声音中加入“感情”元素,让声音听上去更为逼真。
去年Black Hat大会上也展示了一种声音模拟技术,这项技术是通过获取某人长时间的录音,拼接其声音片段实现模拟。阿曼先生表示,虽然很难预测使用AI的网络攻击是否会很快上升,但如果AI技术能够让黑客攻击更成功或更有利可图,他们会更倾向于使用该技术。
基于神经网络和机器学习的AI变声技术
不管是成功诈骗欧洲公司的黑客们利用的技术,还是加拿大的“琴鸟”(Lyrebird),它们最终都能得到高还原度的合成声音,在这背后依赖的技术正是神经网络(Neural Network)和机器学习(Machine Learning)。
神经网络通过模拟电信号在人脑神经元之间的传递过程,对输入数据进行处理,同时利用分层的神经元,从大量样本数据中总结出共同特征。
第一个用神经网络生成人类自然语音的,就是Google的DeepMind研究实验室发布的WaveNet。

接下来就以WaveNet为例,简单介绍一下AI是如何通过神经网络和机器学习来合成语音的。
论文链接:
https://arxiv.org/abs/1609.03499
WaveNet是基于PixelCNN的音频生成模型,在这个生成模型中,每个音频样本都以先前的音频样本为条件。条件概率用一组卷积层来建模。这个网络没有池化层,模型的输出与输入具有相同的时间维数。
在模型架构中使用临时卷积可以确保模型不会违反数据建模的顺序。在该模型中,每个预测语音样本被反馈到网络上用来帮助预测下一个语音样本,由于临时卷积没有周期性连接,因此它们比RNN训练地更快。
使用临时卷积的主要挑战之一是需要很多层来增加感受野,为了解决这一难题,作者使用了加宽的卷积,加宽的卷积使只有几层的网络能有更大的感受野。模型使用了Softmax分布对各个音频样本的条件分布建模。
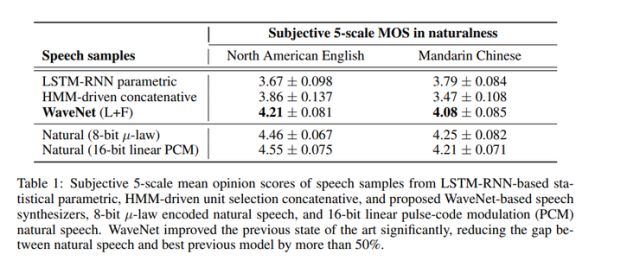
这个模型在多人情景的语音生成、文本到语音的转换、音乐音频建模等方面进行了评估。测试中使用的是平均意见评分(MOS),MOS可以评测声音的质量,本质上就是一个人对声音质量的评价一样。它有1到5之间的数字,其中5表示质量最好。
相关检测技术正在研究中
联合国区域间犯罪与司法研究所人工智能与机器人中心主任Irakli Beridze表示,将机器学习技术应用于欺骗性声音使网络犯罪变得更加容易。
联合国中心正在研究检测虚假视频的技术,Beridze先生称这对于黑客来说可能是一个更有用的工具。“想象一下,以CEO的声音进行视频通话,这是您熟悉的面部表情,这样的话你根本不会有任何疑虑。”他说。
推特上有网友对此也发表了看法,认为可以利用AI技术破除AI难关,或许这会成为未来解决类似问题的主要办法之一。
在百度上输入“语音诈骗”、“识别”等关键词,可以看到百度经验的相关帖子,虽然这些“经验”都已经相当古早,但能看出大家与这类诈骗的对抗已然是相当持久。
不管怎样,希望相关的识别技术能早日研究出来。
不知道大家有没有遇到过类似的语音诈骗事件?当真的遇到这类事件应该如何应对最好呢?欢迎大家留言讨论。
本文转载来自36kr.com。
